Blaze: Holistic Caching for Iterative Data Processing
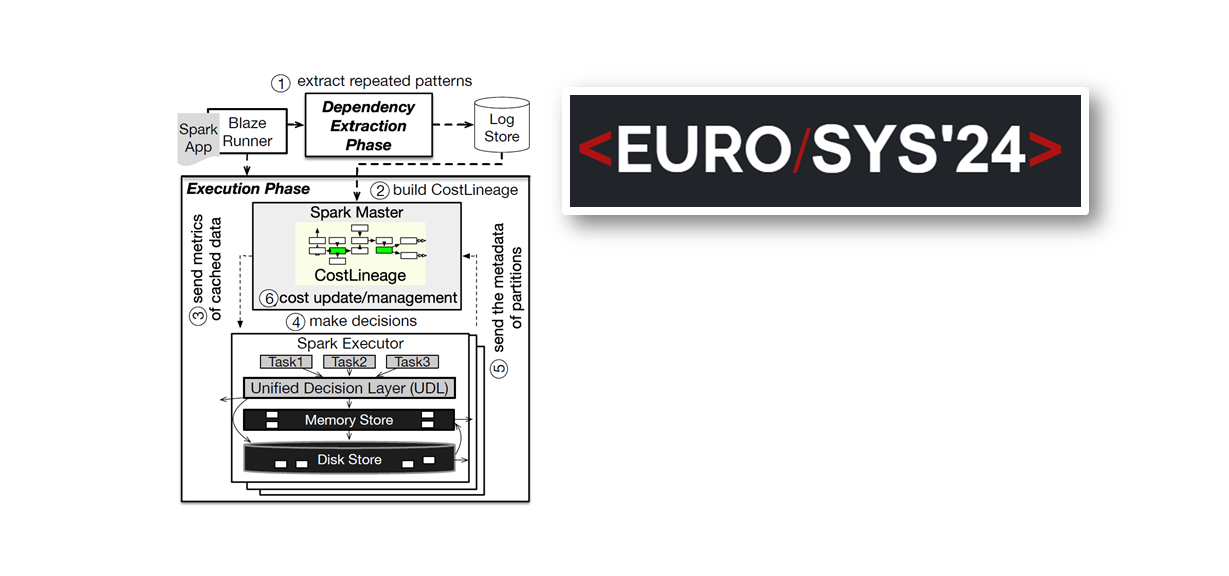
Abstract: Modern data processing workloads, such as machine learning and graph processing, involve iterative computations to converge generated models into higher accuracy. An effective caching mechanism is vital to expedite iterative computations since the intermediate data that needs to be stored in memory grows larger over iterations, often exceeding the memory capacity. However, existing systems handle intermediate data through separate operational layers (e.g., caching, eviction, and recovery), with each layer working independently in a greedy or cost-agnostic manner. These layers typically rely on user annotations and past access patterns, failing to make globally optimal decisions for the workload. To overcome these limitations, Blaze introduces a unified caching mechanism that integrates the separate operational layers. Blaze dynamically captures the workload structure and metrics using profiling and inductive regression, and automatically estimates the potential data caching efficiency associated with different operational decisions based on the profiled information. To achieve this goal, Blaze incorporates potential data recovery costs across stages into a single cost optimization function, which informs the optimal partition state and location. This approach reduces the significant disk I/O overheads caused by oversized partitions and the recomputation overheads for partitions with long lineages, while efficiently utilizing the constrained memory space. Our evaluations demonstrate that Blaze can accelerate end-to-end application completion time by 2.02 − 2.52× compared to recomputation-based MEM_ONLY Spark, and by 1.08 − 2.86× compared to checkpoint-based MEM+DISK Spark, while reducing the cache data stored on disk by 95% on average.