

December 16, 2025 / by admin / In people /
ORBITFLOW is accepted to VLDB 2026
ORBITFLOW is accepted to VLDB 2026, 52nd International Conference on Very Large Data Bases.
VLDB*
The Very Large Data Bases (VLDB) is a premier annual international forum for data management, scalable data science, and database researchers, vendors, practitioners, application developers, and users. The forthcoming VLDB 2026 conference is poised to deliver a comprehensive program, featuring an array of research talks, keynote and invited talks, panels, tutorials, demonstrations, industrial tracks, and workshops. It will cover a spectrum of research topics related to all aspects of data management, where systems issues play a significant role, such as data management system technology and information management infrastructures, including their very large scale of experimentation, novel architectures, and demanding applications as well as their underpinning theory.
Key areas of interest for PVLDB include, but are not limited to, data mining and analytics, data privacy and security, database engines, database performance and manageability, distributed database systems, graph and network data, information integration and data quality, languages, machine learning, ai, and databases, novel database architectures, provenance and workflows, specialized and domain-specific data management, text and semi-structured data, and user interfaces. These thematic pillars represent the foundational elements underpinning the technological landscape of the emerging applications of the 21st century. (cites link)
OrbitFlow*
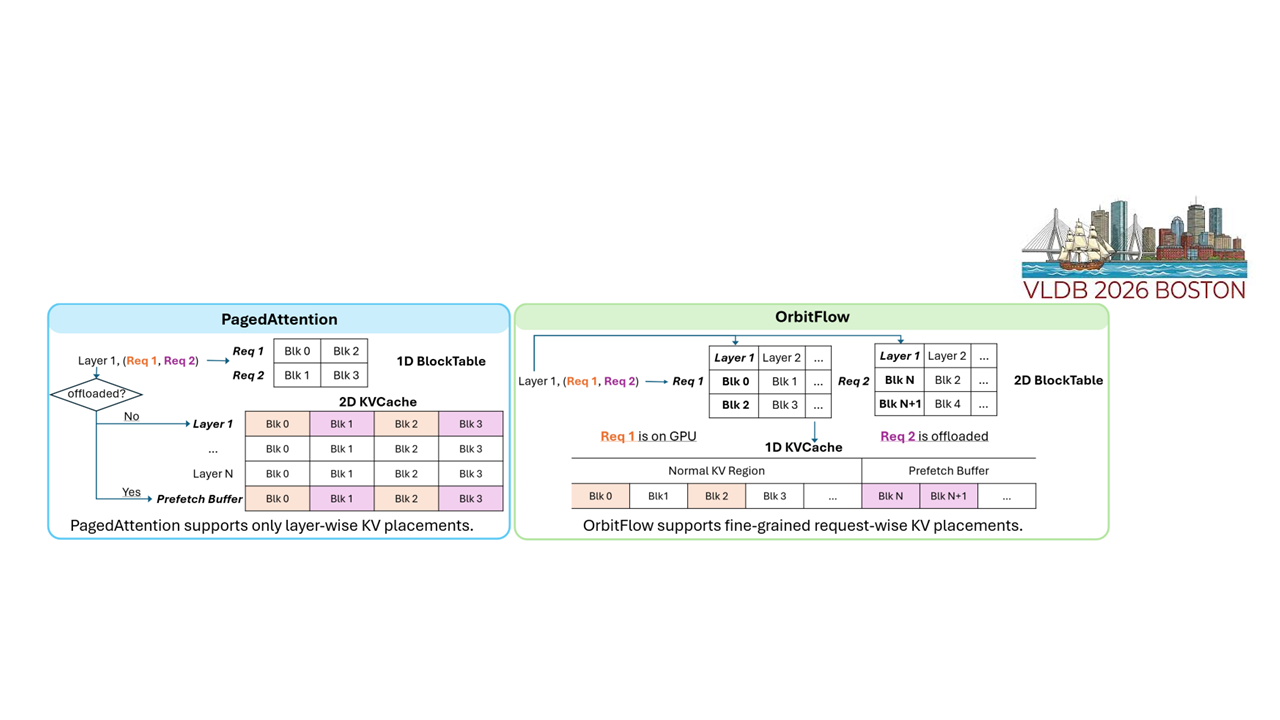
Serving long-context LLMs is challenging because request lengths and batch composition vary during token generation, causing the memory footprint to fluctuate significantly at runtime. Offloading KV caches to host memory limits effective GPU memory usage, but existing static and predetermined offloading strategies cannot adapt to the rapidly shifting memory demands of long-context serving. This often leads to excessive CPU-to-GPU KV transfers that translate into latency spikes and frequent SLO violations. To address these challenges, we introduce OrbitFlow, a finegrained and adaptive KV cache management system that meets latency SLOs in long-context LLM serving. OrbitFlow employs a lightweight ILP solver to decide which layers’ KV caches to retain on the GPU for each request, within memory capacity constraints. It continuously refines KV placements based on runtime feedback when the active plan becomes suboptimal during token generation. Under heavy load, OrbitFlow invokes a fallback mechanism to temporarily defer in-flight requests with large memory footprints, preserving overall SLO attainment. Our experiments demonstrate that OrbitFlow improves SLO attainment for TPOT and TBT by 62% and 66%, respectively, while reducing the 95th percentile (i.e., P95) latency by 38% and achieving up to 3.3× higher throughput compared to existing offloading methods.
Who are main authors?
Among the authors, Xinyue Ma and HeeLim Hong are main authors of OrbitFlow. Xinyue Ma is MS-PhD student in OMNIA lab. For more details about her, please refer link. And HeeLim Hong is MS-PhD student in OMNIA lab. Also, for more details about him, please refer link.